Septième épisode

🎙️ Écoutez cet épisode sur Apple Podcast, Spotify ou ci-dessous si vous le préférez. 👇
Il est intéressant de penser l’évolution du livre comme celle d’une disparition progressive de sa matérialité. L’évanouissement de sa forme physique n’est rien moins que l’objectif de Jeff Bezos quand il propose que la Kindle fasse oublier le support de la lecture tout en faisant surgir le monde de l’auteur. Mais si d’aucuns aiment le livre dans son aspect matériel, il faut se rappeler que la force de la forme du livre est de constituer un support invisible ou disons qui s’invisibilise au profit de l’histoire, le contenant s’effaçant pour laisser place au contenu.
Reste que ce livre physique est un objet dont la forme a connu de multiples évolutions, mais la plupart allant vers une décroissance matérielle, du moins si l’on considère les deux extrêmes que pourraient représenter la tablette de cire il y a quelques milliers d’années (on ne parlera même pas de l’origine minérale de l’écriture que l’on retrouve dans l’étymologie du mot « calcul ») et le livre de poche aujourd’hui, ultime avatar d’un objet auparavant lourd des matériaux que constituaient les feuilles non de papier mais d’origine animale (c’est le sens du mot « vélin » venant de « veau »), reliure de cuir, fermoir métallique, etc. De ce point de vue, quelle ne fut pas ma surprise d’apprendre il y a quelques jours en lisant le New York Times (vous ai-je dit que j’avais gagné un abonnement ?) que certains ouvrages avaient des reliures d’origine humaine. J’aimerais bien un jour prendre le temps d’explorer un peu plus l’évolution des supports et des matériaux utilisés dans la fabrication des objets du quotidien.
Quoi qu’il en soit, nous avons ainsi abandonné ou sommes en train ou certains sont en train d’abandonner la matérialité du livre qui, en devant numérique, n’est jamais qu’une somme de 0 et de 1 remplaçant des processus de fabrication auparavant organique puis végétal. Mais c’est justement ce processus industriel qu’il me semble important de rappeler. L’ouvrage physique de papier est le résultat d’une technologie et, à qui l’oublierait, j’aime montrer les usines produisant un tel support. Mais précisément, c’est une technologie qui se fait oublier et qui se place exclusivement en amont de la production livresque. Après, en aval de cette production, la technologie s’efface, on l’a vu, et n’offre rien au lecteur sinon sa disparition volontaire.

Or, justement, ce que j’aime dans le livre numérique, ce sont ces moyens intangibles, c’est-à-dire numériques, enrichissant l’expérience de la lecture. Le livre numérique offre des possibilités d’interaction inédites. C’était tout le sens du précédent article montrant comment une application comme Readwise aspirait les passages soulignés et annotés pour me les remettre en mémoire à intervalles réguliers. Nous avions terminé en évoquant l’application de prise de notes Obsidian, application dans laquelle je consigne mes petites pensées nourries de mes lectures, et dans laquelle, grâce à Readwise, je retrouve les extraits soulignés ainsi que les annotations prises au cours de ces mêmes lectures.
Nous avions aussi, souvenez-vous, évoqué le Graph View qui permet de visualiser et naviguer dans ses données. Évidemment, l’ensemble n’a pas qu’une valeur esthétique. Et si vous aimez les trucs du type MySQL ou encore les formules du genre Query dans Google Sheets, vous serez en terrain familier et pourrez faire pas mal de choses avec vos notes, notamment avec le plugin Dataview.
Nous allons donc à présent entamer un chapitre un peu technique et voir quel parti le lecteur peut tirer de la technologie, comment on peut plonger dans ses données ou encore utiliser l’intelligence artificielle. On verra également qu’il est possible de transformer le lecteur en « power user » utilisant des scripts pour automatiser de nombreuses tâches. Bien sûr, rassurez-vous, chatGPT écrit les scripts pour vous ! Si jamais vous trouvez que la chose est trop complexe, on peut se tourner vers Automator ou encore Raccourcis. Les possibilités sont multiples.
Plongée dans les données
Je pense que lorsque l’utilisateur d’Obsidian découvre pour la première fois le plugin Dataview et qu’il comprend ce qu’il peut en faire, son petit corps de geek est pris de soubresauts de contentement incontrôlables.
Si vous ne connaissez pas la chose, je vous invite à regarder la vidéo An Introduction to Dataview.
Mais sachez qu’avec Dataview, on peut transformer le dossier dans lequel se trouvent toutes vos notes en une base de données et ainsi effectuer diverses requêtes. Il s’agit d’une méthode de recherche très puissante et qui permet d’obtenir, par exemple, une liste et même un tableau de toutes ses notes, et bien plus encore grâce à un code et donc une syntaxe qui, pour l’essentiel, est assez facile à comprendre. En tout cas, si je l’ai comprise, vous pouvez le faire. Je ne dis pas que tout est facile, mais les commandes de base sont faciles à comprendre, et jusqu’ici, elles m’ont suffi amplement. Le reste, dois-je avouer, est hors de ma portée.
Pour que cela fonctionne, il faut que vos notes possèdent des métadonnées. À cet effet, on utilise le format YAML. Ces métadonnées sont le plus souvent placées par l’utilisateur en tête des notes et peuvent inclure différentes informations comme l’auteur, la version, les tags, etc.
Toutefois, certaines notes ont déjà par défaut des métadonnées, sans qu’il soit nécessaire de les insérer à la main. C’est le cas du jour de création (file.cday) ou du nom (file.name).
Avec Dataview, on va pouvoir extraire toutes ces données et les afficher dans des listes ou des tableaux. Voici comment procéder.
Dans Obsidian, pour insérer le code de Dataview, on place, sur une note, trois accents graves suivis du mot « dataview » signalant le début et l’on place à nouveaux trois accents graves indiquant la fin. Tout ce qui se trouve entre les deux constitue le code de Dataview.
```dataview
LIST
FROM "Documentation/Intelligence artificielle" AND #éducation
WHERE file.cday > date(2023-01-01) AND file.cday < date(2023-11-04)
SORT file.name ASC
```
Décomposons un exemple.
LIST
Tout d’abord, je demande à Dataview d’établir une liste de toutes mes notes. On écrit donc simplement le mot LIST (en anglais, sans « e » donc).
FROM
Mais comme je ne veux pas avoir une liste de toutes mes notes, mais seulement certaines, je précise que je veux uniquement les notes provenant du dossier Documentation dans lequel on trouve le dossier Intelligence artificielle. Dans ce dossier, toutes les notes sont consacrées à l’IA, mais certaines ont le tag #éducation, et ce sont celles-là que je veux. On écrit donc : FROM "Documentation/Intelligence artificielle" AND #éducation.
WHERE
Je veux uniquement les notes écrites entre le 1er janvier 2023 et le 11 novembre 2023 et écris donc : WHERE file.cday > date(2023-01-01) AND file.cday < date(2023-11-04).
SORT
Les notes sont classées par ordre alphabétique. Il nous faut alors ajouter : SORT file.name ASC (« ASC » signifiant « ascending »).
Dans l’exemple que l’on peut voir dans la vidéo ci-dessous, la requête est similaire sauf que cette fois je demande un tableau à trois colonnes dans lequel on trouvera le titre des notes, leur auteur (en général moi) et une évaluation de ces notes (rating). Ce n’est pas que je m’autoévalue, mais cela me donne une représentation visuelle des notes qui me sont importantes sur une période donnée.
Il y a certes une courbe d’apprentissage, mais cela n’a rien d’infaisable. Et je fais le pari que le déploiement des intelligences artificielles va nous faciliter la tâche. On pourra faire ce genre de requête en langage naturel et d’une certaine façon, c’est déjà un peu ce qu’il se passe avec la recherche avancée d’un Google Drive par exemple. Il est donc extrêmement facile de sortir sa boule de crystal et, tout en ne prenant aucun risque, de dire que l’on pourra faire ceci ou cela. On le peut déjà, c’est juste que cela deviendra encore plus facile et plus répandu que ça ne l’est déjà.
À propos d’intelligence artificielle, je voudrais revenir sur une application que nous avons déjà mentionnée et qui s’appelle Readwise Reader.
Readwise Reader
C’est une nouvelle application de Readwise dont nous avons déjà parlé. Elle fait ce que font toutes les applications du type Read-it-later (comme Instapaper ou Pocket…). Elle vous permet de sauvegarder les articles que vous souhaitez lire (tout en supprimant les publicités, les menus…) voire les lire hors-ligne, les annoter ou les archiver.
Qu’est-ce que l’intelligence artificielle vient faire là-dedans ?
Dans Readwise Reader, vous pouvez convoquer Ghostreader, qui est alimenté par GPT.

Vous pouvez alors faire de nombreuses choses. Par exemple, vous pouvez résumer un article, ce qui me semble pratique avant (on peut se dire « Voyons. Apprenons-en davantage sur ce que contient cet article avant d’éventuellement lui consacrer du temps ») et après la lecture (« Au fait, de quoi cet article parlait-il déjà ? »).

On peut encore faire bien d’autres choses. On peut poser une question (imaginez la plus-value pour un élève ou un étudiant qui a dans cette fonction la possibilité d’interagir avec le texte comme il le ferait avec un tuteur : « Explique-moi telle ou telle partie que je n’ai pas bien comprise. », « Donne-moi davantage de détails sur tel point »).
Si l’on tapote sur un mot ou un passage que l’on a souligné, on obtiendra encore d’autres fonctions assez étonnantes, comme la possibilité de transformer ce passage en flashcard.

Mais ma préférée est probablement la lecture audio des textes sauvegardés. Au début, cette fonction me laissait de marbre et puis un jour tout a changé. Ça s’est passé comme ça : j’étais dans le métro. J’étais en train de lire un article qui me passionnait quand j’arrivai à la station où il me fallait descendre du train. Je regrettais de devoir différer ma lecture quand je me suis exclamé (en mon for intérieur naturellement) : « Mais suis-je bête ! Il me suffit d’écouter l’article au lieu de le lire ! »
Certes la lecture par une intelligence artificielle n’est pas la plus séduisante qui soit, mais la technologie Text To Speech s’est considérablement améliorée. C’est de mieux en mieux, et pour l’instant c’est bien suffisant pour prendre connaissance d’un contenu et éviter une interruption indésirable. C’est aussi un nouveau mode d’interaction avec le texte. Désormais, il m’arrive donc de lire debout, en marchant, sans regarder le texte.

Il existe une autre fonction qui me plaît énormément et que j’aurais aimé avoir en tant qu’étudiant. En effet, après la lecture (après un certain temps en fait, quand la courbe de l’oubli a fait ses ravages), il peut être opportun de vérifier que l’on se souvient de ce qu’on a lu. Dès lors, demandons à l’IA de générer des questions qui poussent à la réflexion.
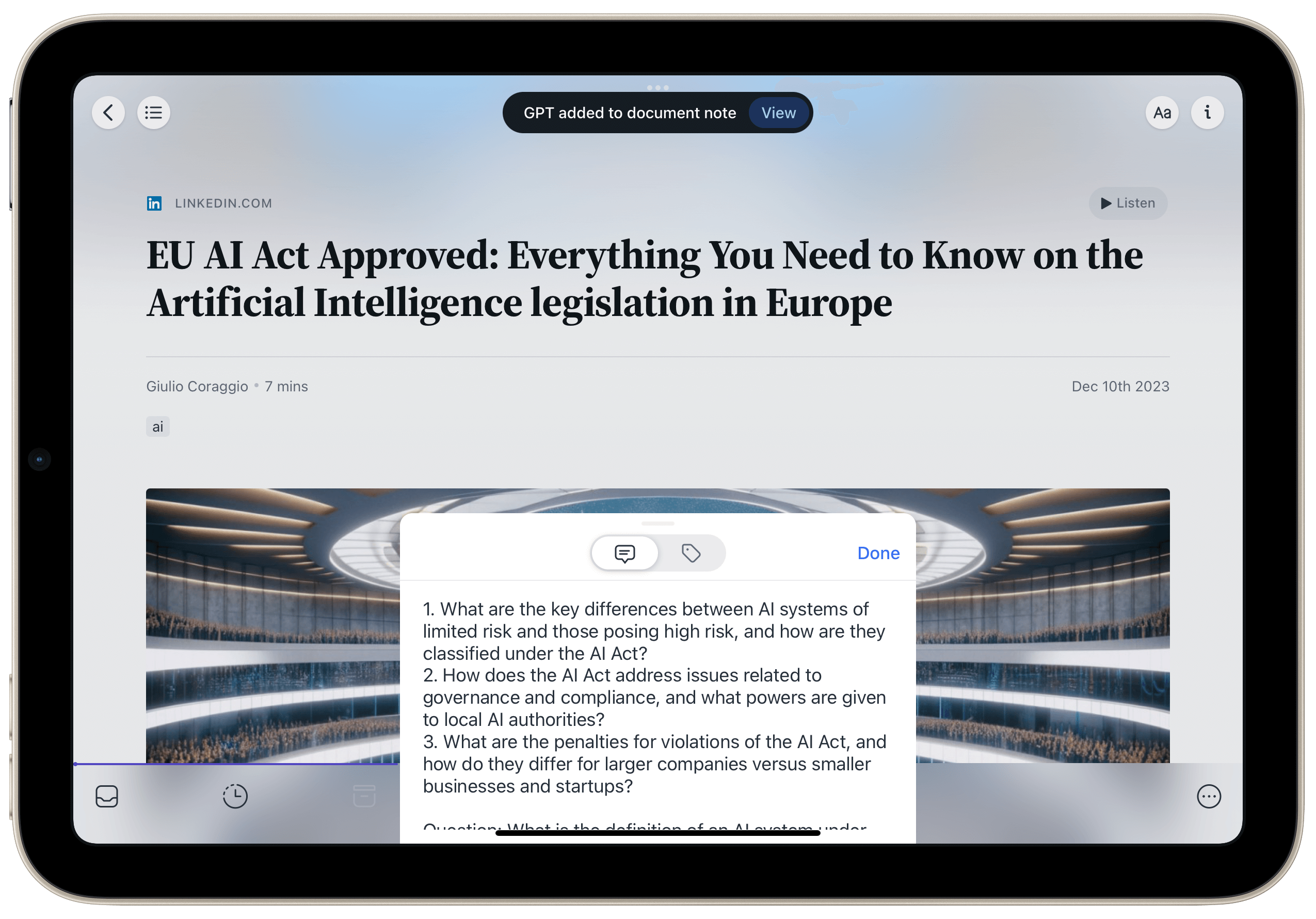
Vous vous souvenez de ce que nous avons dit à propos de la répétition espacée ? Il en va de même pour l’IA. Elle aide à mieux apprendre. Testez vos connaissances aussi souvent que possible pour vous assurer que vous vous souvenez sur le long terme des textes que vous avez lus.
Mais pour cela, j’ai trouvé encore bien mieux avec le plugin Text Generator pour Obsidian.
Text Generator
J’ai découvert ce plugin en lisant l’article Photoshop for text. Ce que Steph Ango, l’auteur de l’article dit est très intéressant :
Lorsque je pense à l’édition d’images, un large éventail d’options me vient à l’esprit : contraste, saturation, accentuation, flou, aérographe, clonage, etc. Même les éditeurs d’images de base offrent des dizaines d’outils de manipulation d’images utiles.
Lorsque je pense à l’édition de texte, une définition beaucoup plus étroite me vient à l’esprit : couper, copier, coller, trouver, remplacer, vérifier l’orthographe – rien qui ne modifie la totalité de l’écriture. Cette définition est en train de changer.
Et en effet, l’IA permet de manipuler le texte dans des proportions inédites. Mais revenons à Text Generator. En gros, ce plugin me permet d’utiliser GPT-4 dans Obsidian et donc dans mes notes.
Cela signifie que l’on peut faire tout ce que nous avons mentionné précédemment. On peut demander n’importe quoi au sujet de ses notes. Mais ce que j’aime le plus, c’est la possibilité d’obtenir un quiz. Je peux ainsi convoquer Text Generator et dire par exemple : « Pose-moi 5 questions sur cette note concernant Vygotsky » (note que j’ai prise il y a quelque temps durant ma lecture et pour laquelle je veux mesurer le degré de rétention).
Ainsi, lorsque je sens que les connaissances que j’ai acquises dans un livre s’estompent, je retourne à mes notes, je les lis et je demande un test.
Je me suis efforcé de documenter le fonctionnement de ce plugin dans cette note, si cela vous intéresse. Vous y trouverez un petit script permettant de faire ce que nous venons d’évoquer.
Apple Script
J’ai toujours rêvé de savoir écrire des scripts. Malheureusement, je suis trop occupé ou trop feignant pour apprendre. Or chatGPT est très fort en la matière, et je l’utilise dès que j’ai un truc un peu technique à faire, RegEx par exemple. Ou encore l’écriture d’un script.
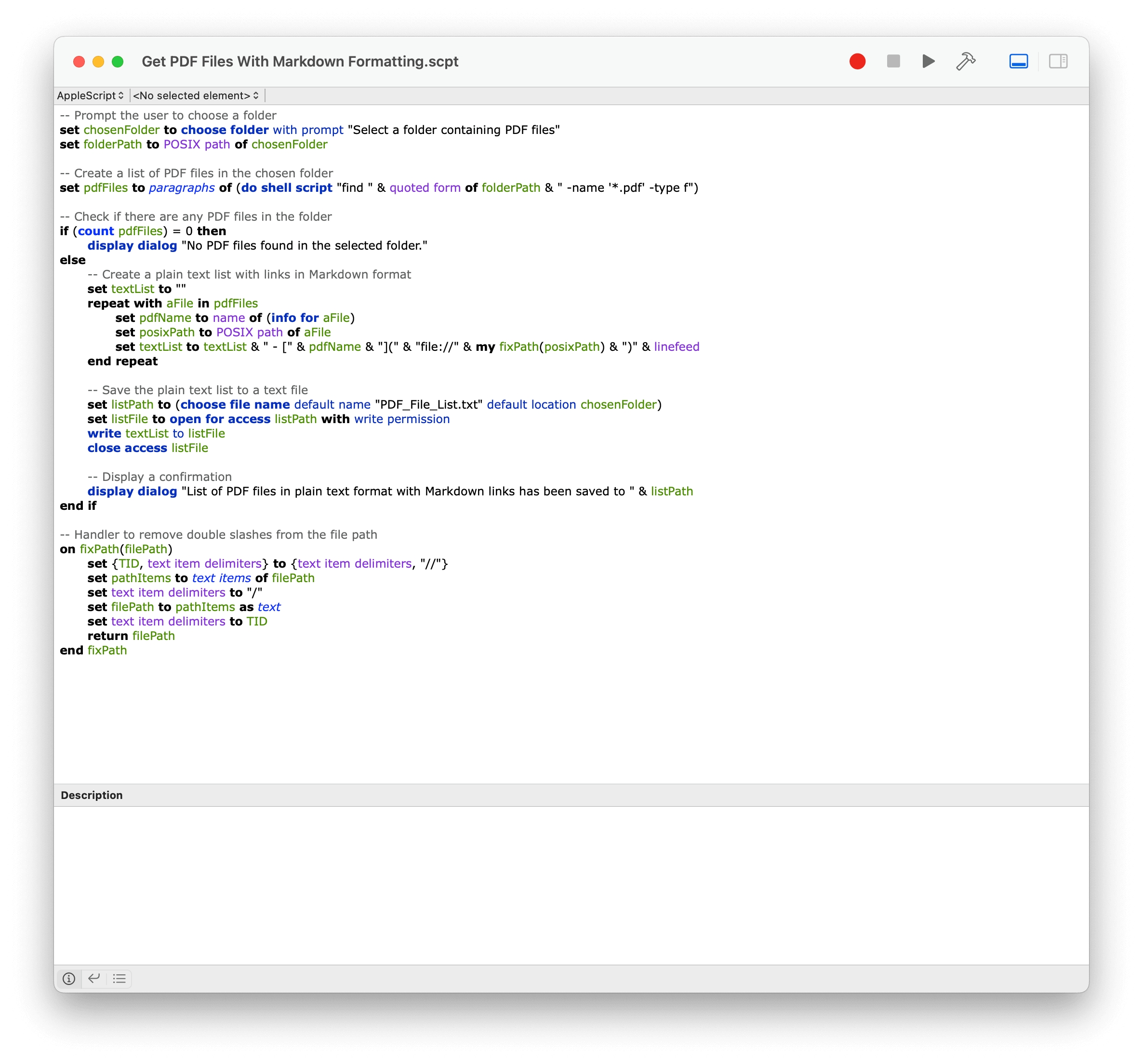
Voici un exemple pour lequel on cherche à avoir une liste des PDF que l’on a téléchargés et obtenir les liens au format Markdown pour placer tout cela dans Obsidian.
Le prompt a été écrit en anglais mais cela doit pouvoir se faire en français sans problème.
Give me an apple script providing a list of pdf files in a specific folder the script asks me to choose. Use the POSIX path for the file links and make sure that each link has the full path (i.e. "file:///Users/…"). Then I would need to export this list which must be a bulleted list built with dashes. Create a new line for each item.
Le script ressemble à ceci et j’aurais été bien en peine de l’écrire. Quant au « POSIX path », je ne suis pas bien certain de savoir ce que c’est, mais cela a été suggéré par chatGPT après quelques essais infructueux au cours de nos discussions. Si cela vous intéresse, j’ai donné d’autres exemples ici.
Dans un cas, cependant, chatGPT a échoué à créer le script demandé et m’a conseillé de m’en remettre à Automator. Voici le prompt.
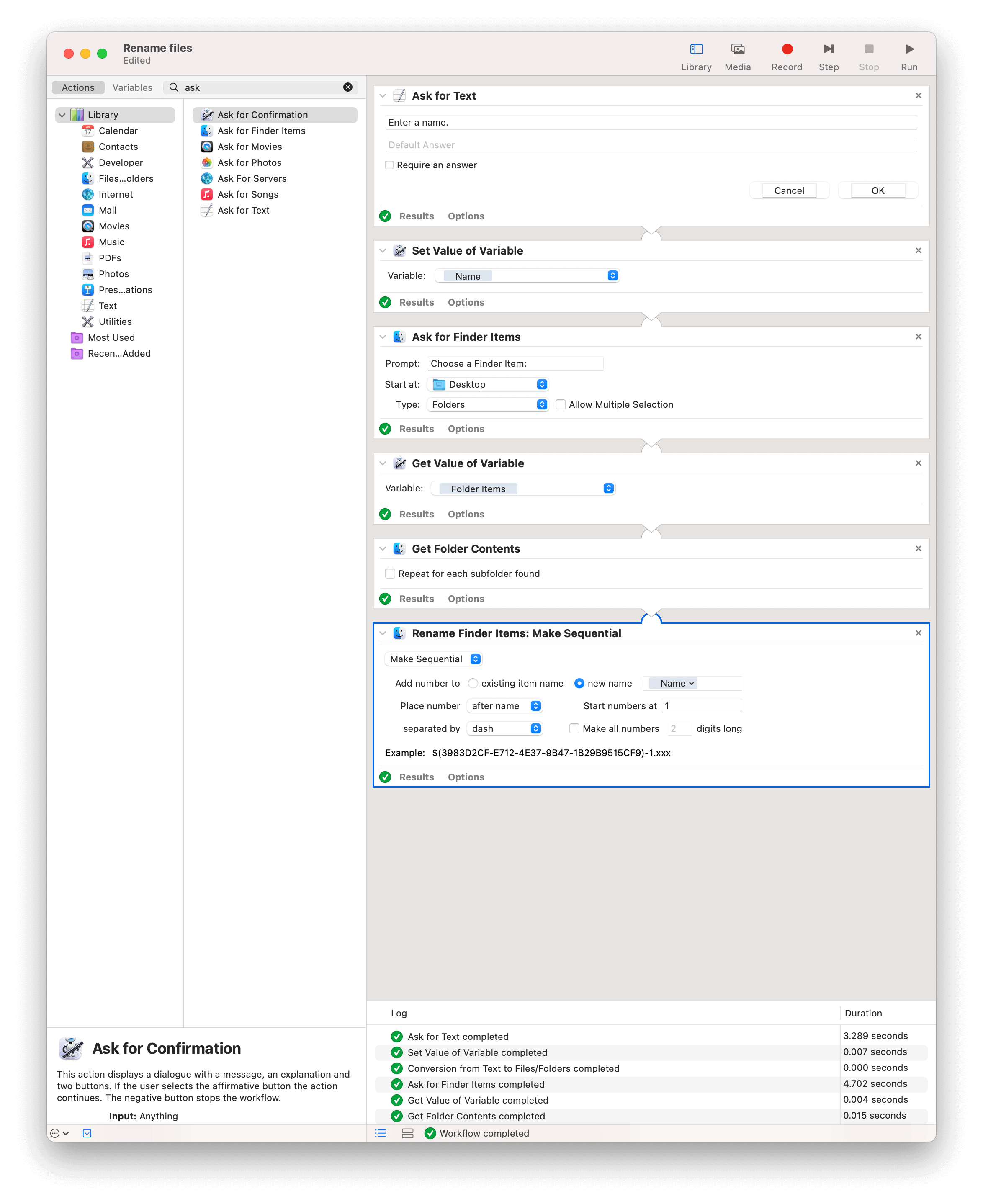
Write an apple script asking the user to select a folder and to pick a name. Then, the script renames each files with this name and a number (1 for the first file, 2 for the second one and so on). Ignore files like ".DS_Store."
Et j’ai finalement abouti à ce script produit par Automator qui fait tout à fait l’affaire.
Raccourcis
Automator, en son temps, avait déjà été conçu pour permettre, "for the rest of us", de créer simplement une automatisation, c’est-à-dire un enchainement de tâches qui, si l’on doit les répéter plusieurs fois, méritent d’être automatisées. On va plus vite et on réduit le risque d’erreurs. Malheureusement, son inventeur Sal Soghoian a été licencié par Apple et je ne sais pas combien de temps encore on pourra s’amuser avec Automator. Toutefois, on a (et ce aussi bien sur Mac que sur iPad ou iPhone) l’application Raccourcis. Ce n’est pas sans évoquer des applications comme Scratch permettant de coder avec des blocs.
On a pu en voir un exemple d’utilisation dans la partie intitulée Confort de lecture et concentration. Dans l’exemple ci-dessous, je l’utilise pour récupérer les titres des cinq derniers articles consacrés à l’IA dans GoodLinks.
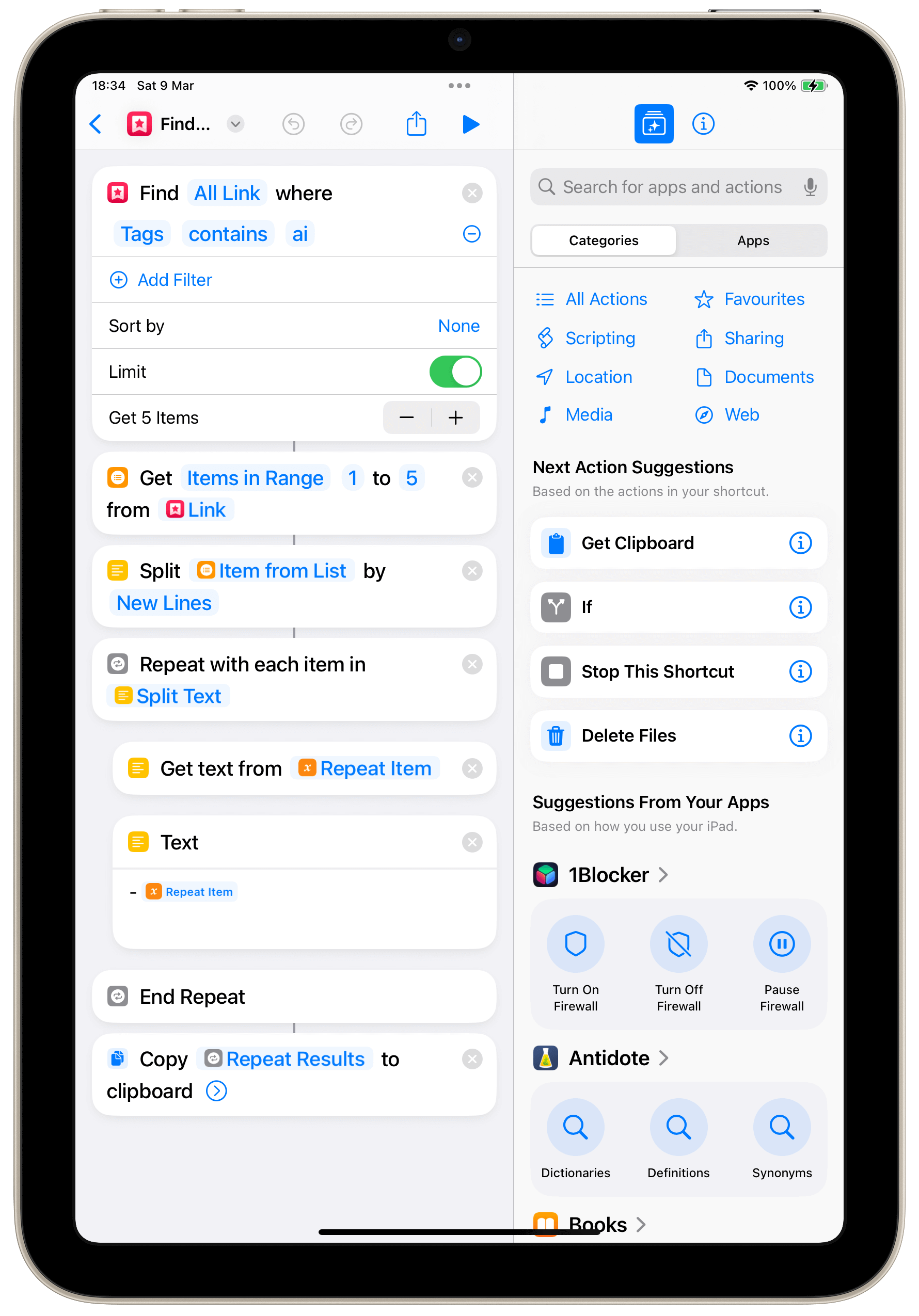
Je souhaiterais l’améliorer en l’utilisant de la façon suivante : le raccourci ira chercher les cinq articles que je placerai, à l’aide d’un tag, dans une liste destinée à être partagée dans l’une des newsletters que j’écris, et je récupérerai les liens des articles par la même occasion au format Markdown.
Voilà !
Nous avons terminé de passer en revue différentes méthodes d’automatisation ou différents recours à l’intelligence artificielle, processus qui tous nécessitent du lecteur de nouvelles compétences techniques, mais qui je crois en valent la peine. On l’a dit, l’automatisation permet d’aller plus vite et de réduire les erreurs. On a pu voir que nombre de ces automatisations avaient trait aux PDF que je télécharge çà et là, c’est bien pratique de pouvoir les renommer, les retrouver, les sélectionner ou obtenir des liens dûment formatés si besoin. On a vu enfin que l’IA offraient des possibilités nouvelles au lecteur qui peut interroger le texte, le résumer ou obtenir un quiz à son sujet. Que ce soit en termes d’organisation ou de vérification de la solidité des connaissances, j’y vois pour le le lecteur, on l’a dit, certes un besoin d’acquérir de nouvelles compétences mais aussi et surtout un moyen de renforcer les connaissances acquises. Bref, comme on le disait au début de cette série, de devenir un meilleur lecteur.
Faut-il devenir un geek pour autant ?
Non, je ne le crois pas, mais comme on la vu avec Steph Ango, les définitions, que ce soit celle de l’écriture ou celle de la lecture, sont en train de changer et des possibilités nouvelles dont on aurait tort de se priver apparaissent.